RavenDB... What am I persisting, what am I querying? (part 2)
Part 1
Part 2 I want to discuss Relationships & References, and the difference between the two.
Part 3
Taking from part 1's example, lets add a User to the mix:
public class Order
{
public string Id { get; set; }
public string UserId { get; set; }
public string DateOrdered { get; set; }
public string DateUpdated { get; set; }
public string Status { get; set; }
// Other properties...
public IEnumerable<OrderLine> Lines { get; set; }
}
public class OrderLine
{
public int Quantity { get; set; }
public decimal Price { get; set; }
public decimal Discount { get; set; }
public string SkuCode { get; set; }
// Other Properties
}
public class User
{
public string Id { get; set; }
public string Username { get; set; }
public string Password { get; set; }
public string FirstName { get; set; }
public string Surname { get; set; }
// Other Properties
}
As you can see I've added 'UserId' to the Order, not a 'User' just the Id part. This is because I don't want direct access to the User. (It is possible to map a User in RavenDB, but I don't believe that is always a good idea. Save it for special occasions.)
If we were modelling this in a Relational Database, we would have a relationship between Order and User, add some foreign keys, and if we threw an ORM into the mix we would probably have an Order object looking like:
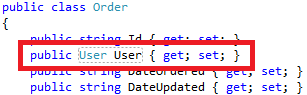
Where we wire up the User object inside the Order. This in the long run lets to all sorts of problem. Then we would eager load the User when we fetch the order, maybe on the order we need to fetch the product, so on and so forth. It just gets messy and complicated.
So rather than adding the User object to the Order, in RavenDB we would just add the UserId. But why are we doing this? Below I have modelled the Relational Database Table Structure.
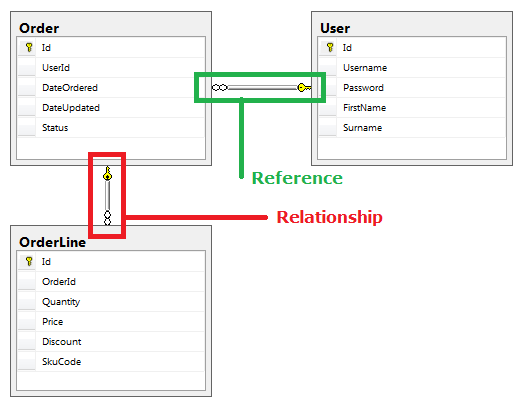
As you can see I've highlighted two Foreign Keys. But I've named them both differently, one is a reference and one is a relationship.
Reference
The reference has no real purpose other than to maintain referential integrity in the database. Not for our sake, but mainly because we want to keep our DBAs happy. The problem with this however, is we don't actually need it. An order can still exist in the system without a User. We still know who paid for it by the billing information, and we know who it was shipped to from the shipping information.
Maybe the user wanted to specify what email or phone number to contact them. This information isn't information that belongs to the user. The only reason we have 'UserId' is to so when that user logs into the application, we know which orders belong to him, the information on those orders don't relate to the User other. This is not a relationship, it's a reference. A reference to the User.
Relationship
The next one is the Relationship, and it has a real purpose beyond referential integrity. An OrderLine really can't exist without an Order. Without an order it has no meaning or purpose. The problem is because there are multiple Lines to a single Order, we need to persist them in their own table.
An OrderLine might have a Reference to Product, but an OrderLine can exist without the Product. Since an OrderLine relates back to an Order, you don't have a real need to ever load an OrderLine by itself. You may edit/delete lines, but that will always be done via the Order.
This ultimately creates a Root Aggregate, the Order becomes the Root while the Lines become the children, and an OrderLine is always loaded with an Order, but never on it's own.
User/Product Data Duplication
First thing you may think by having the First/Last name of the User on the Addresses, or the Addresses data copied into the Order's Billing/Delivery Address, is duplicating data. Same with taking a Products Price/Name/SKUCode and putting it on the OrderLine.
This isn't data duplication.
If a user changes his name, you have a Reference to the user still, but at the time he billed his order, he was John Doe, not John Snow. His address may have changed but we captured it at the point of ordering. This is information that belongs to the Order, not to the User. The fact we have the same name in both the User and Order is a mute point, because visually they are the same, but from a business perspective, they are not the same.
Benefit of Duplicating
So we are copying data now. Is this a good thing? Well lets think about it in an Order History screen.
If a user logged in, went to their account history and viewed their previous order:
Using a relational database, no copying data.
In the scenario using a relational database, we would use the selected OrderId to load the Order, eager load the OrderLine. Fetch the User, Addresses, Product.
Fetching all this data could be done multiple different ways, but already we are asking for a lot of data. A lot of which we aren't using.
Then we have to compose a lot of that data together, or maybe we joined it and created a new object for displaying it all.
Using a document database, copying the data.
In the scenario of using a document database, we would query for the Order using the OrderId. And begin displaying all the data.
We already knew the Product name that was captured and used at the time of purchase, but we would have the ProductId to reference it back to the Product in the system.
We already know who it was shipped to, and who it was billed to.
We don't need to find the User or the Product or the Addresses or anything like that. We have all the information for that Order.
In my next post I'll talk about loading References. This one is already long.
Again I hope this makes sense, feel free to comment and ask questions :)
comments powered by Disqus